Published
Writing Archive
Browse the current post archive and published long-form notes from the dedicated blog backend.
Open archiveBio
I am a first year Ph.D student in the Department of Computer Science and Engineering at Seoul National University, advised by Jaesik Park. I am also an incoming research scientist intern at Adobe Research, hosted by Duygu Ceylan and Tuanfeng Y. Wang. Before that, I was a research scientist intern at SONY Research, hosted by Takashi Shibuya and Masato Ishii. My research interests lie at the intersection of computer vision and machine learning, with a focus on generative models and multimodal understanding.
Full bio ▼I received my M.S. degree from Seoul National University, advised by Jaesik Park, and was honored with the Best Thesis Award. During my master's, I worked as a research scientist intern at Microsoft Research Asia with Chong Luo and Qi Dai.
I earned my B.S. in Electrical Engineering and Computer Science from Gwangju Institute of Science and Technology (GIST). During my bachelor's, I was fortunate to be advised by Jonghyun Choi at Seoul National University and Jeany Son at POSTECH. I was also a recipient of the Presidential Science Scholarship.
Latest News
Latest Paper Releases
Vitæ
Full CV in PDF.




Upcoming research internship at Adobe Research, focusing on diffusion models for image and video generation.
Worked on efficient methods for image and video editing, with an emphasis on practical generative editing pipelines.
Investigated video generative models, subject-driven customization, and practical systems for open-domain customized video generation. This work led to an ICASSP 2026 paper and the ECCV 2026 paper, Learning Zero-Shot Subject-Driven Video Generation Using 1% Compute.
Built an early research foundation in computer vision, visual recognition, video understanding, and generative modeling. Published multiple domestic conference and journal papers through KSC, KIMST, and the Journal of KIISE, along with international conference papers including ICCV 2025 and ICCV 2023.
I was grateful to collaborate closely with:
Master's thesis: Advancing Image Editing through Layer-wise Memory in Diffusion. The thesis studied controllable image editing in diffusion models through layer-wise memory mechanisms and was recognized with the Best Master's Thesis Award. Thesis link will be added later.

Took upper-division and theory-oriented coursework including EECS 126, convex optimization, CS 70, and discrete mathematics, along with related courses in probability, algorithms, and computer science foundations.
Graduated 2nd in the Department of Electrical Engineering and Computer Science and received Magna Cum Laude honors. Coursework and undergraduate research focused on machine learning, computer vision, and systems foundations.
* indicates equal contribution. † indicates corresponding authors.
TL;DRGenerates videos of a user-specified subject with no per-subject tuning by separating identity injection (from subject images) and motion learning (from unrelated videos), matching prior zero-shot methods at roughly 1% of the compute.

TL;DRA large open dataset for reference-image-guided editing, built via "reference completion" — automatically synthesizing the missing reference for existing text-edit triplets to yield ~477K input–reference–instruction–target quadruplets across six edit categories.
TL;DRReconstructs dynamic 3D humans and their surrounding scene over time from only a few low-overlap cameras, using camera-controlled video diffusion to synthesize dense novel views and reconstructing background and people separately with cross-view tracking.
TL;DRTackles open-domain customized video generation — synthesizing videos of user-specified subjects across arbitrary domains — with an end-to-end ecosystem spanning data, model, and evaluation.

TL;DRIntroduces online event-boundary detection for streaming video (unlike prior methods that need the whole clip), with an Event-Segmentation-Theory–inspired model (ESTimator) that flags boundaries where its frame predictions diverge from what actually happens.

TL;DREditing methods built for U-Net diffusion fail on multimodal diffusion transformers (MM-DiT); this work analyzes MM-DiT's text–image attention to build an editing method handling global-to-local edits across MM-DiT variants, including few-step models.

TL;DRSupports long, multi-step image edits by storing past edits in a layer-wise memory, with background-consistency guidance and multi-query disentanglement so objects can be added or removed with rough masks while keeping earlier edits intact.
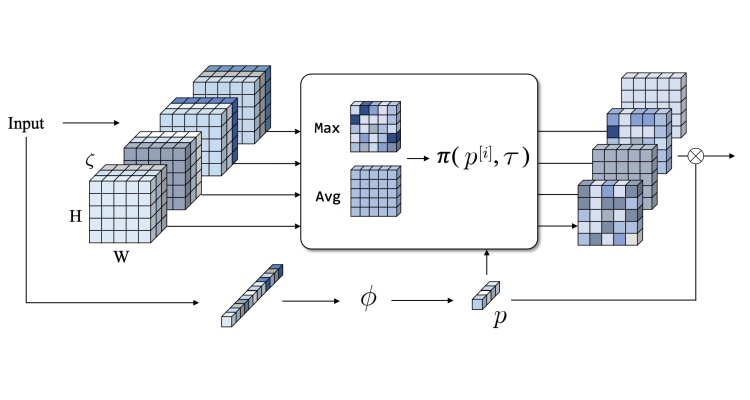
TL;DRReplaces costly 1×1 channel-squeeze layers in ConvNets by splitting channels into subsets and dynamically picking per pixel based on the input — about 25% faster at comparable accuracy, and reusable as a downscaler and dynamic pruner.
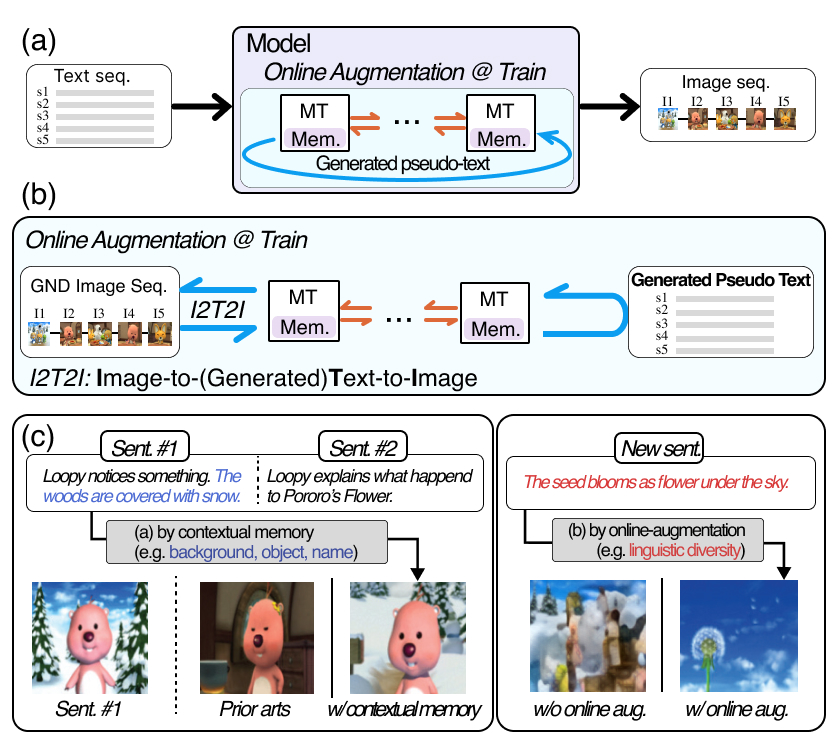
TL;DRGenerates coherent image sequences from multi-sentence stories using a context-memory module that propagates information across frames and an online text-augmentation scheme that creates pseudo-descriptions during training, improving long-term consistency.
Feel free to reach out for research discussions, collaboration ideas, or anything related to visual generation and multimodal learning.
You can also reach out to my advisor Jaesik Park for any collaboration.
Published notes stay public. The private writing studio now uses the shared admin session and the unified Mac backend gateway.
Published
Browse the current post archive and published long-form notes from the dedicated blog backend.
Open archiveAdmin
Sign in, draft posts, publish entries, and manage the local writing backend without touching other services.
Open private studioProject Access
Leaderboard
2026.03 ~ Present
Submission and ranking dashboard for the 2026S Introduction to Machine Learning assignment.
Open leaderboardPrivate Project
2026.04 ~ Present
Telegram-like web chat hosted on the Mac mini with a single shared admin account and one managed gateway entrypoint.
Open PocketChatPrivate Project
2026.04 ~ Present
Private group daily video check-ins with same-moment multi-view slots, invite-only sharing, and an end-of-day recap built for close circles.
Open Pocket LogPrivate Project
2026.04 ~ Present
Private writing studio backed by the Mac mini, now routed through the same managed gateway as the other private services.
Open Blog Studio