Our Approach
We view zero-shot SDV-Gen as a dual-task learning problem: identity injection learns subject appearance from subject-image pairs, and motion-awareness preservation maintains video dynamics from arbitrary videos.
Stochastic switching alternates the identity and motion objectives in one training run. During motion updates, random reference-frame sampling and image-token dropout reduce first-frame copying.
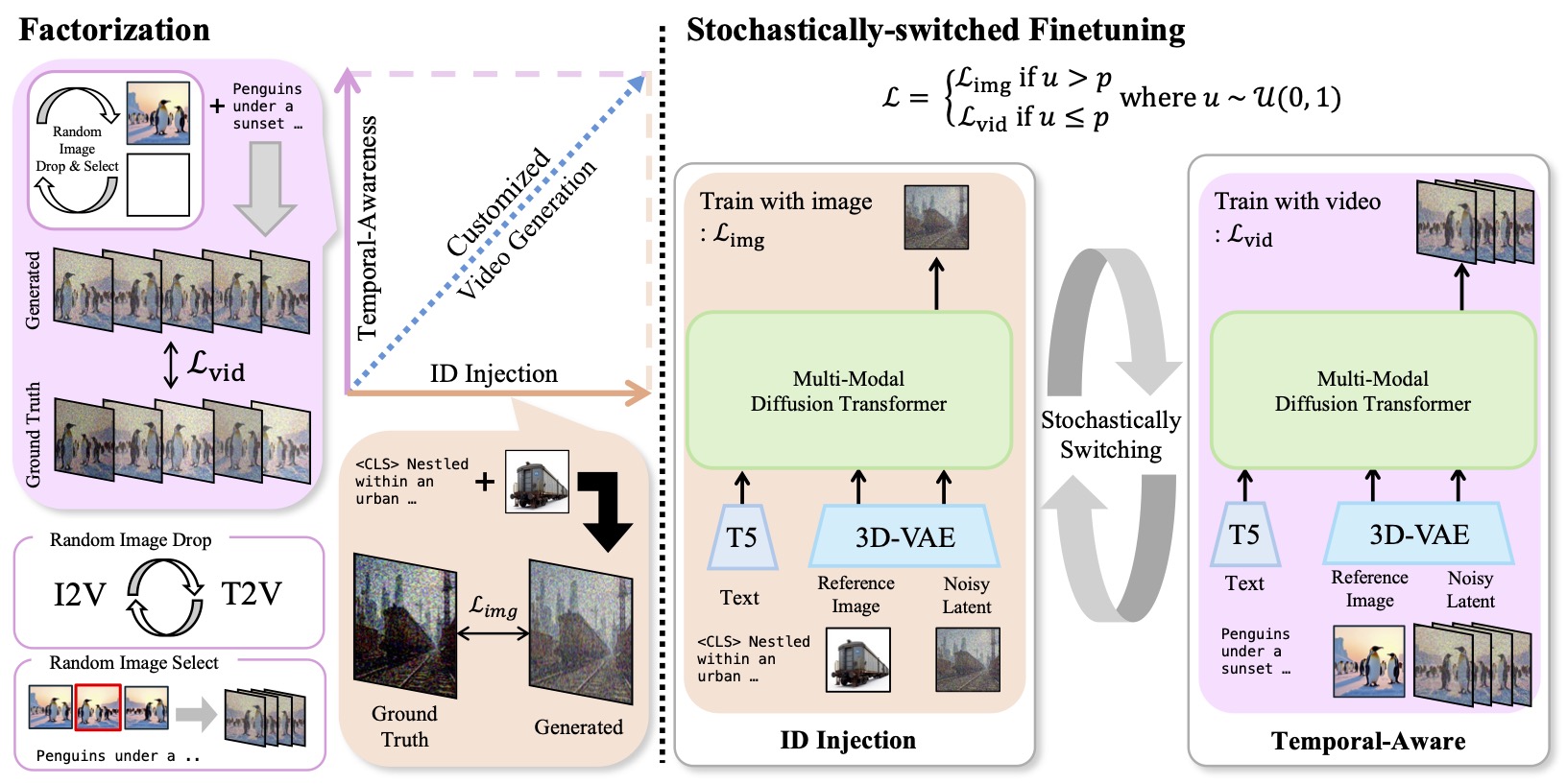
Key points:
- No test-time per-subject tuning and no large-scale subject-video pairs.
- 200K subject-image pairs plus 4,000 arbitrary videos adapt CogVideoX-5B in 288 A100 GPU hours.
- Gradient analysis shows the identity and motion objectives rapidly move toward near-orthogonal update subspaces.